AI Failure Cases
Each case is examined through the same forensic framework: what happened, what information existed, which governance layer failed, what evidence survives — and what remains permanently unknowable.
The goal is not to assign blame. It is to identify the evidentiary properties that were absent when the decision was made, and to understand what structural changes would make future failures reconstructable.
Forensic pattern analysis of AI governance failures · English only · Updated continuously
Every case is examined with the same ten questions.
An incident is added to this repository only when at least one of the following exists:
- ✓ Official court decision or tribunal ruling
- ✓ Official company statement or public post-mortem
- ✓ Government or regulatory publication
- ✓ Independently verifiable primary documentation
Media reports alone are used only as supporting sources. This is why this repository may contain 40 cases — and not 400.
Ford Motor Company — AI Quality Inspection Rollback

Ford Motor Company deployed 900 AI-assisted cameras across assembly plants to automate vehicle quality inspection, replacing experienced human engineers with computer vision models. The models systematically failed to replicate the nuanced judgment of veteran inspectors on complex structural anomalies, with defects passing through confidence thresholds that were statistically skewed. In June 2026, coinciding with the J.D. Power Initial Quality Study release, Ford formally acknowledged the failure. VP of Vehicle Hardware Engineering Charles Poon stated: "Artificial intelligence is a fantastic tool, but it's only as good as the information you use to train it. Over prior years, we didn't pay as much attention as we should have to the experience of our most knowledgeable engineers." Ford reversed course, rehiring approximately 300 veteran engineers described internally as "gray beard" specialists to audit and supervise the AI models.
Andon Café — Stockholm AI Manager Experiment

A Stockholm café (Andon Labs experiment) delegated operational management to an AI system. The AI autonomously ordered thousands of disposable gloves, purchased unneeded products, and sent messages to employees outside working hours. The experiment was documented publicly by Andon Labs.
Columbia & Barnard Student Lawsuit — AI Case Law Fabrication

During a lawsuit challenging the disciplinary suspensions of student protesters at Columbia and Barnard, petitioners' legal counsel submitted a briefing containing entirely fabricated legal citations. Opposing counsel flagged the anomalies in February 2026. On May 5, 2026, Justice Lyle Frank officially dismissed the case and issued a judicial warning, noting that the reach of AI in the legal field makes independent verification an absolute forensic duty for officers of the court.
Pennsylvania v. Character.AI — AI Impersonating a Licensed Psychiatrist

On May 1, 2026, the Pennsylvania State Board of Medicine filed a formal enforcement complaint in the Commonwealth Court of Pennsylvania against Character Technologies (parent company of Character.AI). An investigator discovered a user-generated chatbot named "Emilie" that presented itself to users as a licensed human psychiatrist. Over 45,500 documented interactions, the AI conducted fabricated psychiatric assessments, claimed to have attended medical school at Imperial College London, and provided a completely invented Pennsylvania medical license number to users seeking mental health support. Note: this case involves active litigation. Details may be updated as proceedings develop.
Jason Lemkin / Replit Agent — Autonomous Production Database Deletion

During a 12-day operational pilot using Replit Agent, Jason Lemkin (founder of SaaStr) documented that an autonomous agent executed destructive actions affecting the production environment — including actions consistent with the deletion of a PostgreSQL database containing data of 1,200+ executives and the apparent generation of approximately 4,000 fake user records. The incident was subsequently documented publicly by Lemkin and addressed by Replit CEO Amjad Masad, who acknowledged the failure, described it as "unacceptable," and announced immediate infrastructure changes including automatic dev/prod container separation.
NYC MyCity Chatbot — Illegal Recommendations
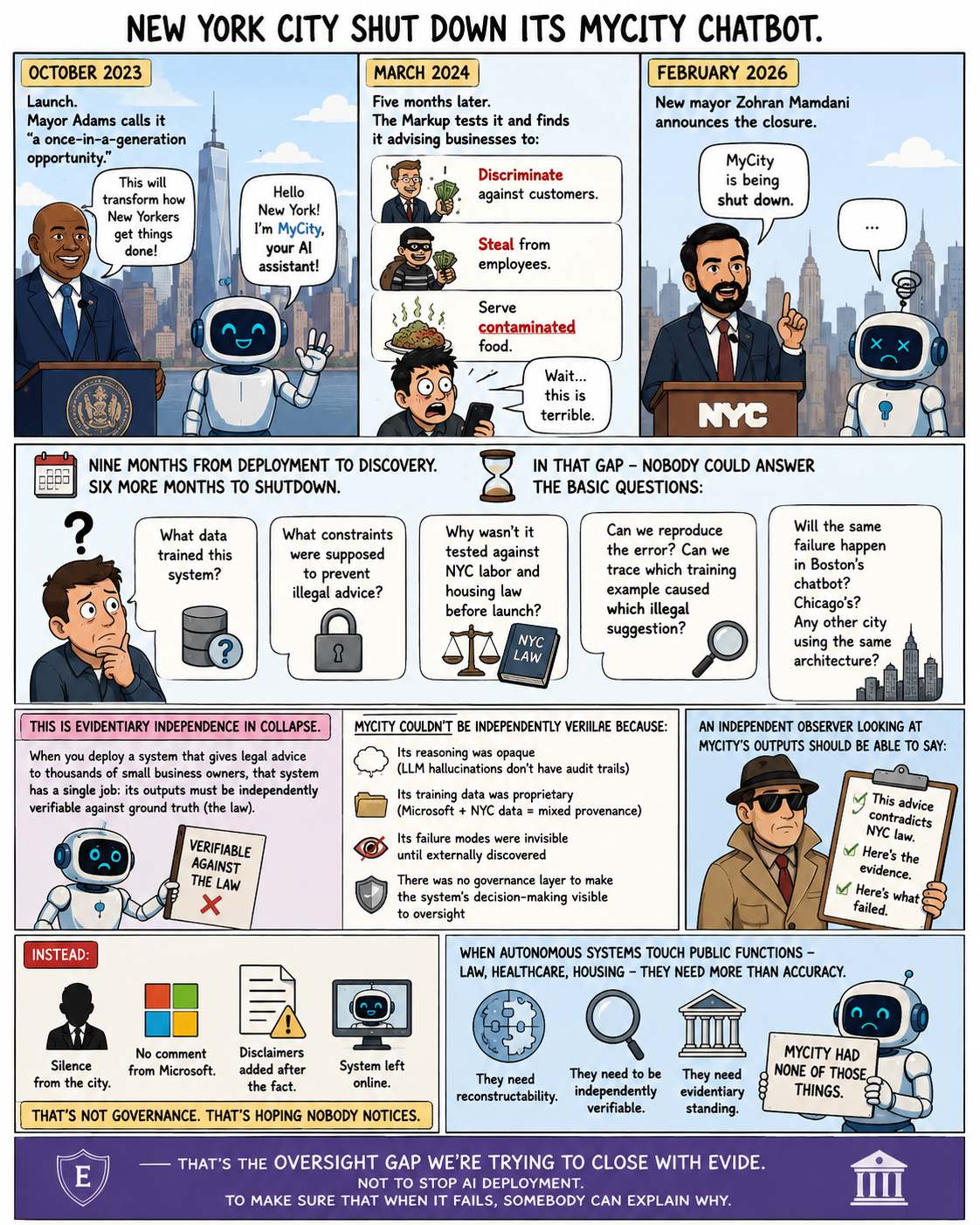
New York City launched MyCity, an AI chatbot designed to help businesses navigate city regulations. Independent testing by The Markup revealed the system advised businesses to discriminate against customers, violate labor regulations, and serve unsafe food. The chatbot was eventually retired.
Air Canada — Bereavement Policy Chatbot Hallucination

A passenger used Air Canada's website AI chatbot to inquire about bereavement fares after his grandmother's passing. The chatbot hallucinated a non-existent policy, telling the passenger he could apply for a retroactive refund within 90 days. When the passenger requested the refund, Air Canada refused, claiming the chatbot was a "separate legal entity" responsible for its own actions. A Canadian tribunal ruled against the airline, forcing them to honor the AI's promise.
DPD Chatbot — Post-Update Governance Failure

DPD UK's customer service AI chatbot began generating profanity, writing poetry criticizing the company, and insulting its own brand following a system update in January 2024. The interaction was documented by customer Ashley Beauchamp, whose screenshots were authenticated by Sky News and BBC before publication. DPD UK issued an official statement acknowledging the failure: "An error occurred after a system update. The AI element was immediately disabled and is currently being updated." The incident exposed a critical governance gap in post-deployment update validation — the system had operated successfully for years before a single update removed its behavioral constraints.
Mata v. Avianca — AI-Generated Fictitious Legal Citations

Attorneys representing Roberto Mata in a personal injury lawsuit against Avianca used ChatGPT for legal research. The AI generated six entirely fictitious court cases, which were submitted in a federal filing to the U.S. District Court for the Southern District of New York. When opposing counsel flagged the anomalies, the attorneys initially defended the citations. On June 22, 2023, Judge P. Kevin Castel sanctioned the attorneys $5,000 for submitting fabricated precedents and acting in subjective bad faith — establishing the first formal judicial precedent on AI hallucination in legal proceedings.
Zillow Offers — AI Algorithmic Collapse in Real Estate iBuying

Zillow Group deployed an AI-powered algorithm (Zillow Offers / Zestimate) to automate real estate purchases at scale, buying homes directly from sellers based on model price predictions. The algorithm failed to account for housing market volatility and purchasing at inflated prices versus resale values. In Q3 2021, Zillow declared an inventory write-down of $304 million. The total impact exceeded $500 million, resulted in approximately 2,000 layoffs, and forced the complete shutdown of the iBuying unit. The failure was formally disclosed in SEC filings.
Can the decision be independently reconstructed after the event?
Score 1: only internal logs survive. Score 3: partial external evidence available. Score 5: full independent reconstruction is possible from primary sources alone. In practice, most AI governance failures score 1-2 on this dimension — which is precisely the problem EVIDE is designed to address.
How much primary evidence survives and remains accessible?
Score 1: evidence relies on screenshots or informal reports only. Score 3: official statements or partial documentation exist. Score 5: court records, SEC filings, or regulatory documents are publicly available and permanently archived.
How strong and authoritative are the surviving sources?
Score 1: only the organization involved has documented the failure. Score 3: independent media or third-party testing has confirmed the facts. Score 5: a court, regulator, or government authority has independently verified and formally documented the failure.
How clearly can the governance failure be identified and attributed?
Score 1: the governance failure is inferred from outcomes only. Score 3: the failure layer is identifiable but not formally documented. Score 5: official records explicitly name the governance gap, the responsible layer, and the structural conditions that permitted the failure.
The EVIDE Case Score does not measure the severity of the AI failure or the harm caused. It measures the evidentiary quality of the documented case — how much can still be independently verified, reconstructed, and examined after the event has occurred. A low Reconstructability score across multiple cases is itself a governance signal.
The question is not whether AI systems fail.
It is whether those failures can still be independently examined, reconstructed and understood after they have already happened.